Attempts to streamline Cross-Encoder for real-time generative AI services and optimization through engineering.
This blog explores optimizing Cross-Encoders for real-time generative AI services. It covers challenges like high computational costs, slower response times, and efficiency issues. Solutions include lightweight techniques—pruning, distillation, and quantization—combined with engineering optimizations, improving response speeds up to 30x while reducing costs and enhancing scalability.
1. Introduction: Challenges of Cross-Encoder in Real-Time Search Systems
1.1 Background
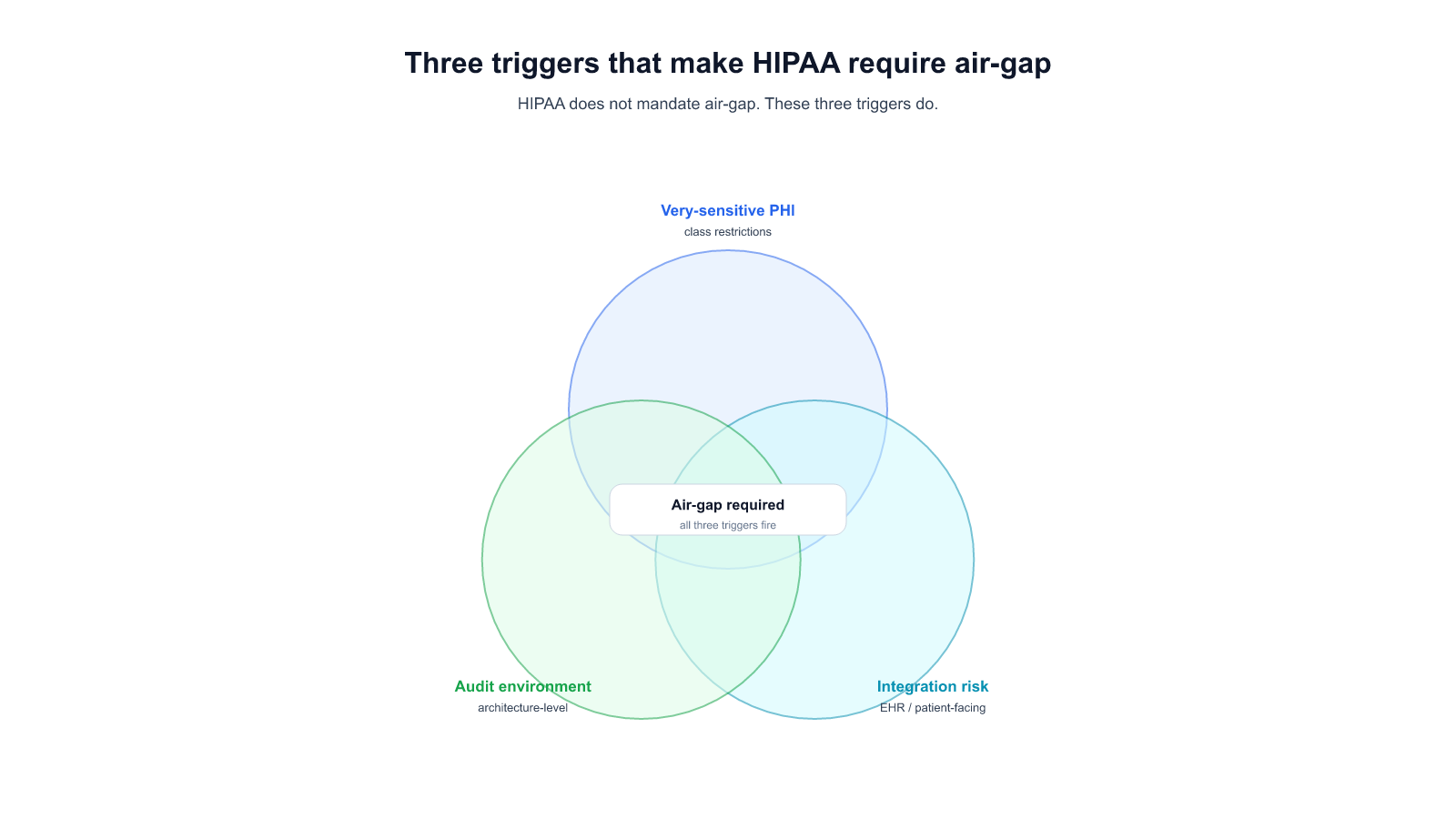
Reranking is a key process in search systems that determines the quality of search results, significantly impacting the end-user experience. Among reranking methods, the Cross-Encoder excels in modeling interactions between queries and documents, offering superior accuracy compared to traditional search models like BM25 and Bi-Encoder.
Cross-Encoders achieve state-of-the-art (SOTA) performance in various applications such as search engines, recommendation systems, and Retrieval-Augmented Generation (RAG), greatly enhancing information retrieval and recommendation quality. Their importance is particularly pronounced in tasks requiring complex queries or a deep understanding of context.
1.2 Necessity
However, the structural characteristics of Cross-Encoders pose significant challenges in real-time search systems:
- High Computational Load:
Cross-Encoders calculate query-document interactions on large datasets, demanding substantial computational resources. This becomes a primary cause of response time delays in real-time search environments. - Increased Computational Costs:
Although reranking is just one stage of the RAG process, excessive resource consumption at this stage can degrade the overall system performance. - Slower Response Time:
In real-time search systems, response time is a critical metric for user experience. Even minor delays can lead to noticeable declines in perceived service quality.
To address these issues, model optimization through lightweight techniques is essential. Representative approaches include pruning, distillation, and quantization, with quantization standing out as a powerful tool for significantly improving speed and efficiency. These optimization techniques reduce the burden of the reranking stage and greatly enhance the scalability and efficiency of real-time search systems.Furthermore, applying deep learning models to real-world services requires consideration of various engineering factors, such as hardware selection, serving platform optimization, and task-specific adjustments.When combining quantization with diverse engineering optimizations, it is possible to achieve speed improvements of up to 10 times or more.2. Challenges of Applying Cross-Encoder to Real-World Services2.1 How Cross-Encoder Works
- Transformer-Based Architecture:
Cross-Encoders utilize Transformer-based language models (e.g., BERT, RoBERTa) to precisely model the relationship between queries and documents. - Input Processing Method:
- Input Format: Queries and documents are combined into a single input sequence in the format: [CLS] query [SEP] document [SEP].
- The final relevance score between the query and document is calculated using the output embedding of the [CLS] token.
- This process allows for comprehensive contextual understanding, resulting in high accuracy.
- Functional Advantages:
- Directly models query-document interactions, enabling more precise evaluations than independent encoding approaches like Bi-Encoders.
- Excels at capturing complex contextual relationships between queries and documents, achieving state-of-the-art (SOTA) performance in search and recommendation systems.
2.2 Structural Characteristics and Challenges of Cross-Encoder
- Computation for Every Input Pair:
- Cross-Encoders process each query-document pair together through the language model.
- As the number of document pairs increases, the computational load scales linearly, reducing efficiency.
- Complexity of Multi-Layer Transformer Operations:
- Typically consists of dozens of Transformer layers (e.g., BERT-Base with 12 layers, BERT-Large with 24 layers), demanding high computational costs.
- The complexity of self-attention operations grows quadratically (O(n²)) with input length, leading to exponential increases in memory usage and inference time when processing long documents.
- Inference Speed and Bottlenecks:
- In real-time systems, the slow inference speed and excessive memory consumption due to handling numerous complex operations can become major obstacles to service deployment.
2.3 Solutions to Cross-Encoder Challenges: Lightweight Techniques
- Pruning:
- Reduces computational load by removing less important model components, such as weights, neurons, attention heads, specific layers, or feed-forward networks.
- May require specialized hardware accelerators, and in some cases, performance can degrade due to computational overhead.
- Distillation:
- Transfers knowledge from a large model (Teacher) to a smaller model (Student) for optimization.
- The Student model learns to mimic the output distributions or intermediate representations of the Teacher, maintaining accuracy.
- However, it incurs additional training costs, and the Student’s performance may not fully match the Teacher’s capabilities.
- Quantization:
- Enhances computational efficiency by converting model weights and activations to lower precision formats (e.g., FP16, INT8).
- Post-Training Quantization (PTQ) minimizes accuracy loss while significantly improving speed and reducing memory usage.
- Quantization is highly effective for meeting the low-latency and resource efficiency demands of real-time search systems and is widely adopted in production environments.
3. Pruning: Reducing Weights and Model Structure
3.1 Concept and Principles

Pruning is a technique that reduces computational load and model size by removing less important components from the model.
In Transformer models, pruning can be applied to specific layers, attention heads, or feed-forward networks (FFN).
The goal of pruning is to maximize computational efficiency while minimizing performance loss.
3.2 Main Types
- Unstructured Pruning
- Removes low-importance values based on individual weights. For example, simplifies computation by setting weights with small absolute values to zero.
- Offers high flexibility, but requires sparse matrix operations, making it highly dependent on hardware and complex to implement.
- Structured Pruning
- Removes structural components of the model, such as neurons or attention heads.
- Maintains dense matrix operations, leading to high hardware efficiency.
- However, structural changes may result in potential performance degradation.
3.3 Advantages
- Reduced Computational Load
- Decreases model size and computational requirements, improving inference speed.
- Particularly effective in mitigating excessive resource consumption in large models.
- Reduced Memory Usage
- Eliminates unnecessary components, thereby reducing memory usage.
3.4 Limitations
- Potential Performance Loss
- Removing critical neurons or weights may significantly degrade model accuracy.
- Constraints of Sparse Matrix Operations
- Unstructured pruning requires hardware capable of accelerating sparse matrix computations.
- If the sparsity ratio is low, the overhead of managing sparse matrices may lead to decreased performance.
- Generally, a sparsity ratio of 70–80% or higher is needed to expect speed improvements, but excessive pruning can cause performance drops.
3.5 Limitations in Service Application
- Structured Pruning
- Alters the model’s structure, increasing the likelihood of performance degradation.
- Unstructured Pruning
- Requires hardware optimized for sparse matrix operations.
- Effective on advanced GPUs like FPGA, NVIDIA A100, or H100.
- However, for H100, annual costs on AWS can exceed $1.35 million, making large-scale real-time service deployment highly inefficient.
- Additional Overhead of Sparse Matrices
- Even if some weights are pruned to zero, effective sparse matrix operations require compression formats (e.g., CSR, CSC).
- When the sparsity ratio is below 50%, the overhead of managing sparse matrices may actually degrade performance.
While pruning can be effective under specific conditions, hardware constraints and overhead issues must be carefully considered when applying it to real-world services.
4. Distillation: Model Compression Through Knowledge Transfer
4.1 Concept and Principles
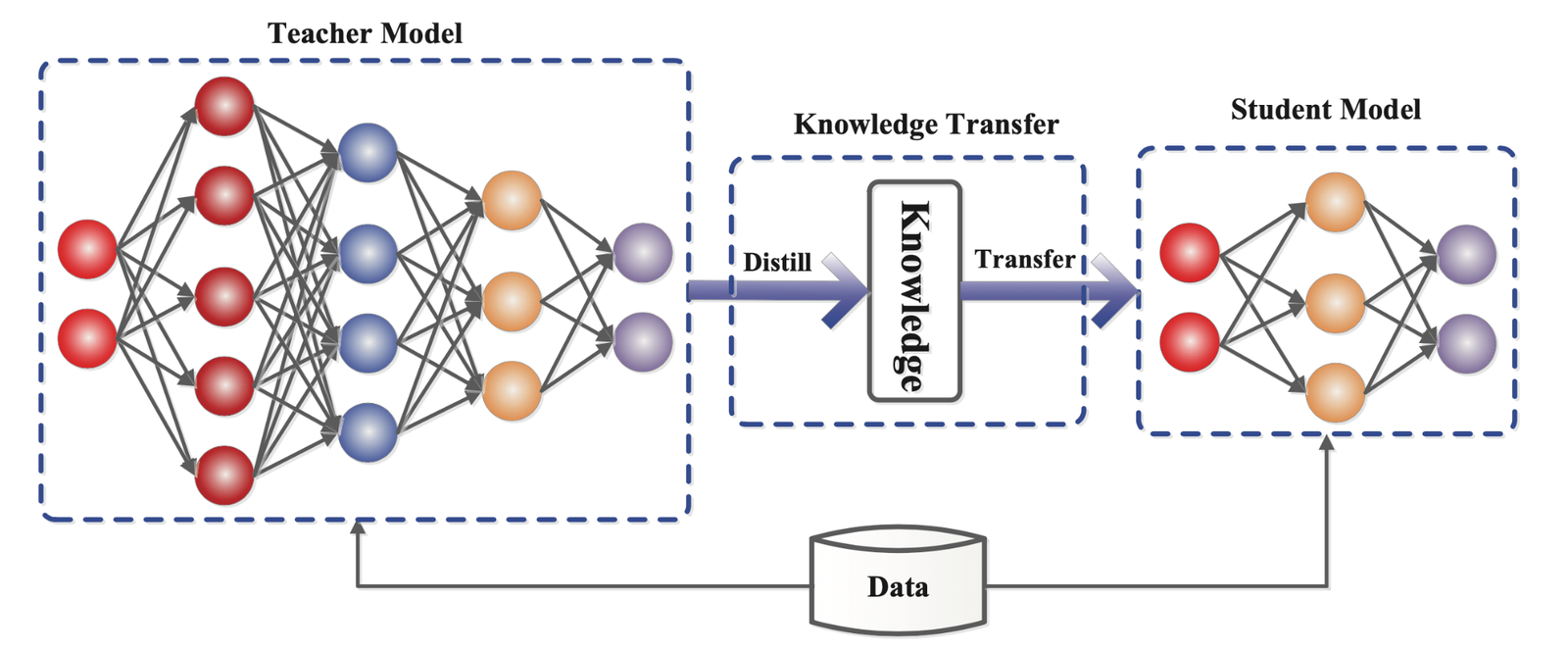
Distillation is a technique that transfers the knowledge of a large model (Teacher) to a smaller model (Student), reducing the model size and significantly decreasing computational load while maintaining accuracy.
The Student model learns from the outputs (soft labels) or intermediate representations generated by the Teacher model, enabling the development of a lightweight model with performance similar to the Teacher.
The reason for using soft labels instead of hard labels (actual data labels) is that soft labels leverage the output information of the Teacher model, allowing for more diverse and enriched learning.

4.2 Main Types
- Output-Level Distillation
The Student model learns from the Teacher model’s final outputs (soft labels).- Example: Simplifying the relevance calculation process by learning the score distributions generated by the Teacher model.
- Intermediate Representation Distillation
The Student model learns from the intermediate layer information of the Teacher model (e.g., attention scores, hidden states).- In Cross-Encoders, attention maps or hidden representations are transferred to the Student model to efficiently convey the Teacher model’s representational capacity.
- Task-Specific Distillation
This method aligns task performance between the Teacher and Student models, creating lightweight models optimized for specific tasks.
4.3 Advantages
- Model Compression
Enables the creation of a Student model with significantly reduced computational load and memory usage compared to the Teacher model. - Versatility
Knowledge learned by the Teacher model can be transferred across various tasks, allowing for broad applications. - Performance Retention
Effectively transfers the Teacher model’s knowledge, enabling the Student model to maintain high performance despite its smaller size.
4.4 Limitations
- Challenges in Complex Knowledge Transfer
The Student model may struggle to fully acquire the high-dimensional representations learned by the Teacher model. - Optimization Difficulties
The Student model often fails to precisely mimic the Teacher model’s prediction distributions, requiring additional training time and resources.- This issue becomes more pronounced as task complexity increases.
- Data Dependency
The performance of the Student model heavily depends on the characteristics of the data used during the distillation process.- If the Teacher model has been trained on diverse datasets while the Student model is trained on a limited dataset, performance gaps may occur.
4.5 Limitations in Service Application
- Training Cost and Time Issues
Research suggests that distilling a Student model to mimic a Teacher model can require thousands to tens of thousands of training hours.- These findings are based on relatively simple image data, and more complex natural language processing (NLP) tasks may demand even greater resources.
- Domain Diversity Challenges
Our services operate across diverse domains in three countries (South Korea, the United States, and Japan).- Distillation may overly optimize the Student model for specific datasets, potentially leading to a decline in overall service quality.
While distillation is a powerful model compression technique, additional considerations are needed to address training time and domain diversity challenges.
5. Quantization: Model Compression Through Precision Reduction
5.1 Concept and Principles

Quantization is a technique that improves computational efficiency and reduces memory usage by converting the weights and activation values of deep learning models into lower precision formats.
By converting numbers represented in FP32 to FP16 or INT formats, it is possible to reduce both computational load and memory consumption.
In large language models, quantization helps alleviate computational bottlenecks and meets the demands of real-time search systems.
5.2 Main Types
- Post-Training Quantization (PTQ)
Converts the weights and activation values of a trained model to lower precision.- Can be quickly applied without additional training, minimizing performance loss while improving computational efficiency through FP16 conversion.
- Dynamic Quantization
Reduces precision dynamically during inference.- Operates only in CPU environments and may be inefficient on accelerators like GPUs.
5.3 Advantages
- Improved Inference Speed
Reduces computational load through lower precision and enables more efficient use of hardware accelerators.- Example: FP16 operations can achieve 2–4 times faster speeds compared to FP32.
- Reduces computational bottlenecks in Cross-Encoders, shortening response times in real-time search systems.
- Reduced Memory Usage
Converting to FP16 reduces memory requirements by more than half.- This provides significant advantages for service scalability.
5.4 Use Cases of Quantization in Allganize Services
Allganize has significantly improved inference speed by applying Post-Training Quantization (PTQ) to convert FP32 weights and activation values to FP16 in Cross-Encoders.
- FP16 PTQ can be easily implemented without additional training and is suitable for reducing memory usage and improving computational speed in GPU environments.
- PTQ maximizes computational efficiency and is considered an effective method for meeting the performance demands of real-time search systems.
5.5 Why Quantization Works Well in Deep Learning
The effectiveness of quantization stems from the fundamental design and learning characteristics of deep learning models, explained as follows:
- Approximate Nature of Deep Learning Models
Deep learning models learn the relationships between inputs and outputs approximately, and minor numerical losses do not significantly impact performance. - Data Uncertainty and Noise Robustness
Even when training data is incomplete or noisy, deep learning models naturally exhibit strong noise tolerance.- Minor numerical distortions caused by quantization are treated like noise, minimizing performance degradation.
- Overparameterization
Deep learning models often contain more parameters than necessary, and small changes in weights do not significantly affect performance. - Activation Functions and Non-Linearity
Activation functions like ReLU and GeLU introduce non-linearity, preventing certain numerical variations from affecting outputs.- Example: ReLU converts negative values to zero, so fluctuations in negative values due to quantization are ignored.
Quantization leverages these characteristics to maximize model compression and efficiency in real-time services.
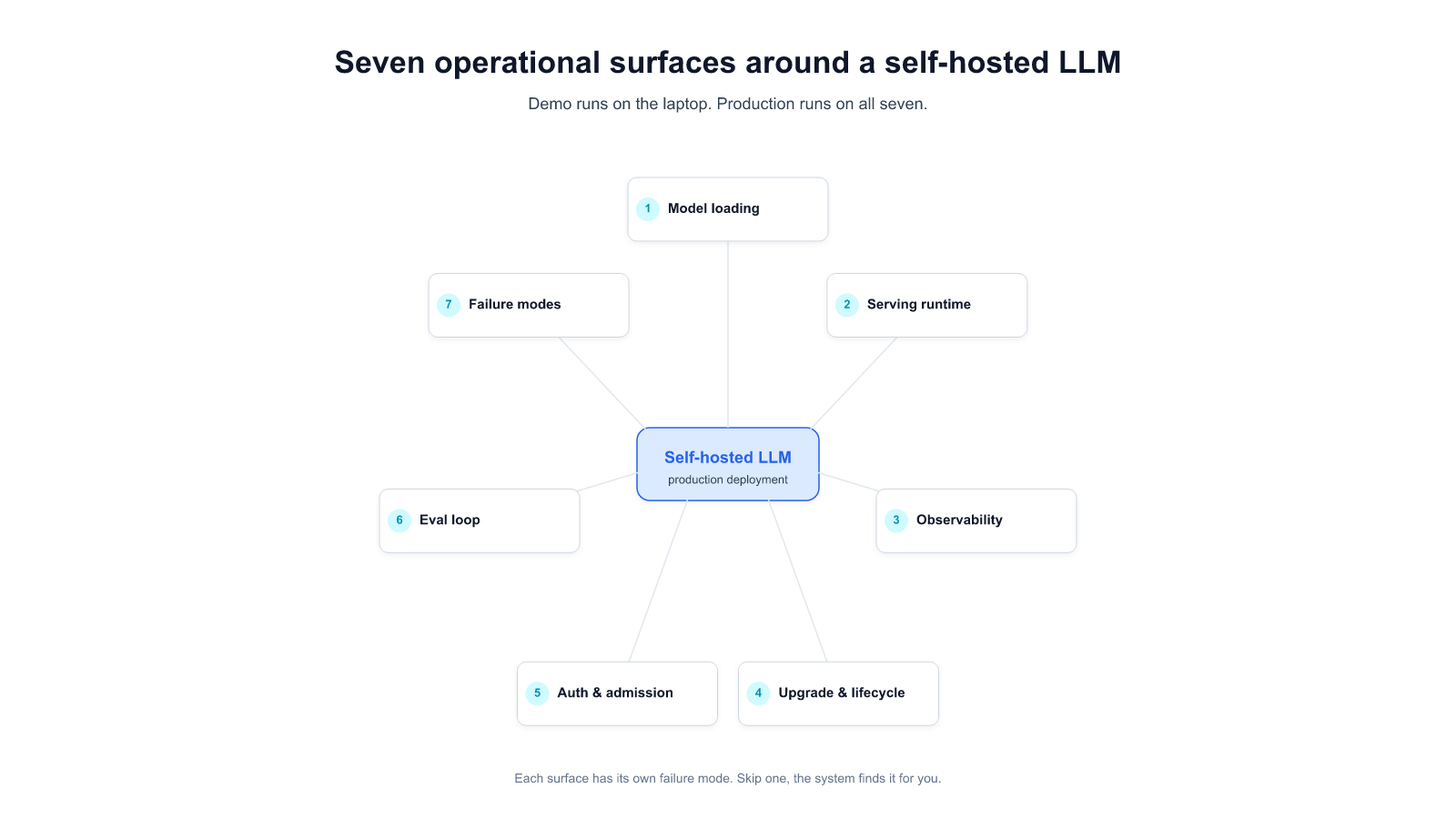
6. Engineering Factors for Providing Real-Time Services
To successfully deploy Cross-Encoder-based reranking in real-time search systems, model compression techniques alone are not sufficient.
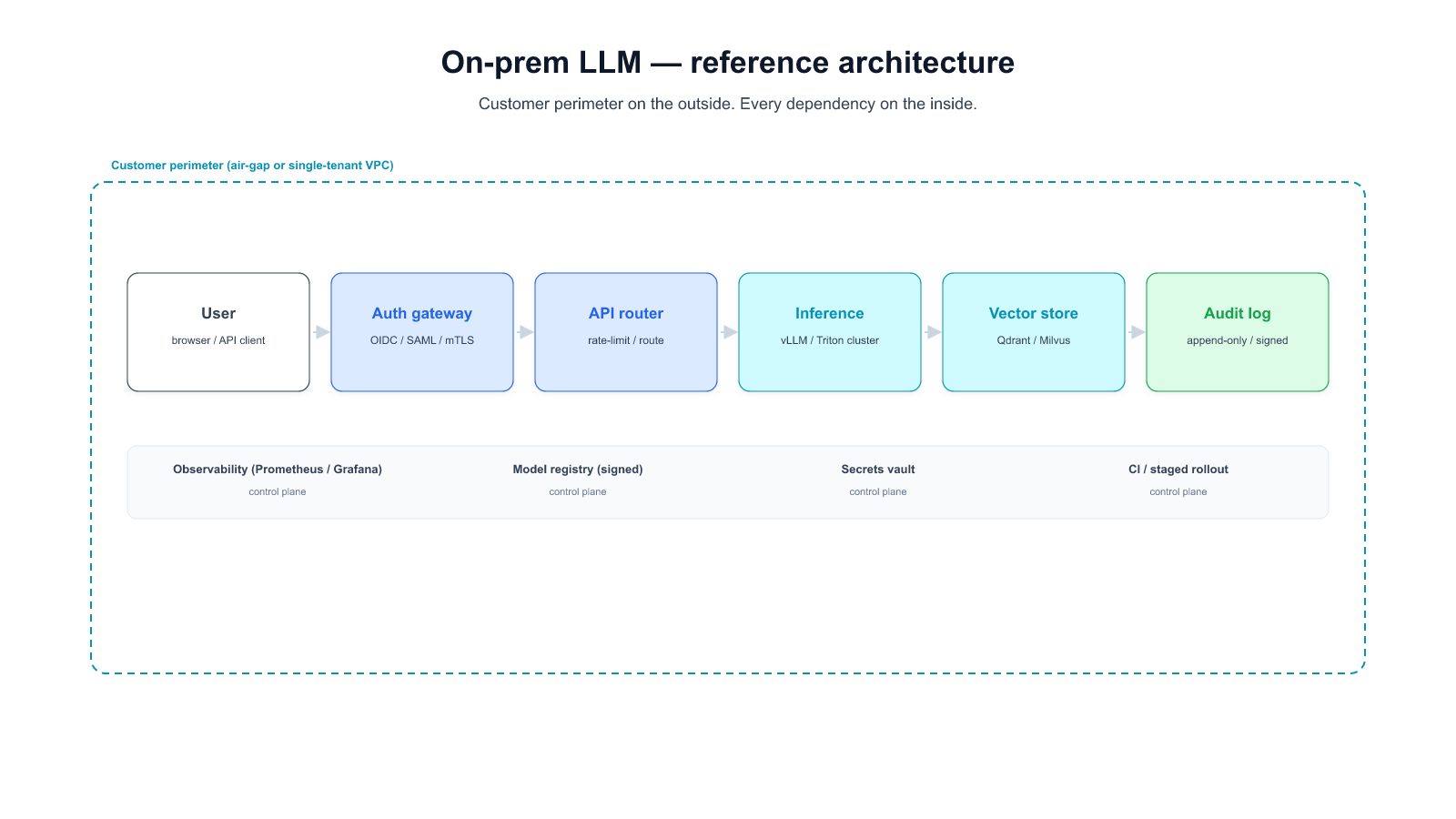
Various engineering factors such as model serving, hardware optimization, and data transfer efficiency must also be considered.6.1 Hardware Selection: L4 GPU
- Efficient Performance
The NVIDIA L4 GPU is designed based on the latest Ada Lovelace architecture, offering robust computational capabilities.
A significant portion of inference time in deep learning models is due to data transfer between the CPU and GPU.
L4 supports PCIe 4.0, doubling data transfer speed compared to PCIe 3.0, thereby alleviating CPU-GPU data transfer bottlenecks. - Cost Efficiency
High-performance GPUs like the A100 offer excellent computational power but are cost-prohibitive for commercial real-time services.
The L4 provides significantly improved performance with lower costs, making it an optimal choice.
6.2 Serving Platform: Triton Server
- Integration with Various Frameworks
Triton Server supports the integration and operation of various frameworks, including TensorFlow, PyTorch, and ONNX, on a single platform.
This reduces the complexity of model management and deployment, enhancing operational efficiency. - Dynamic Batching
Merges multiple requests to maximize GPU utilization while maintaining real-time response speeds. - Scalability and Flexibility
Integrates with Docker and Kubernetes to ensure service scalability and flexibility, with dynamic resource allocation based on predictive load.
6.3 Perceived Speed Improvement Through Dynamic Padding
- Problem Definition
When deep learning models require fixed-size inputs, even small input data must be processed as if it were at the maximum input size, leading to inefficiencies.- Example: If the maximum input token size is 4,096, processing an input with just 100 tokens still requires computations for 4,096 tokens.
- Solution
Introduced Dynamic Padding, optimizing Triton Server to handle inputs of varying sizes efficiently.
Improved the system to perform computations proportional to the actual input size.
After implementation, perceived response speed improved by an average of 20–30 times.
6.4 Quantization
- FP16 Post-Training Quantization
Reduced precision from FP32 to FP16, decreasing computational load and memory usage, and significantly improving inference speed.- FP16 operations are optimized on the L4 GPU, maximizing efficiency.
6.5 Optimization Results
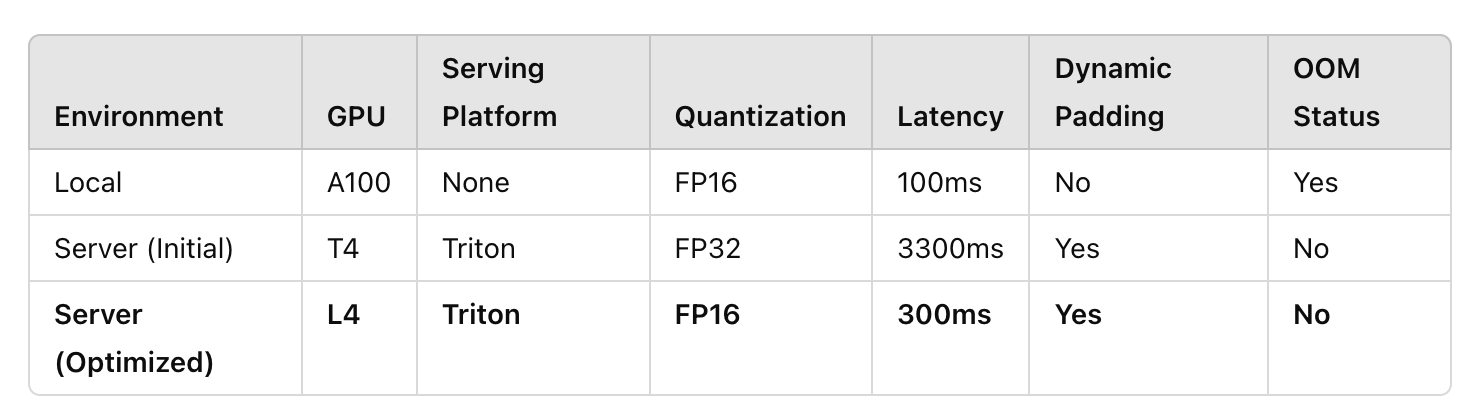
Optimization Results Summary
- Performance Improvement
By optimizing various factors such as hardware (L4), serving platform (Triton), dynamic padding, and quantization, the overall response speed improved by over 10 times, with perceived speed enhanced by 20–30 times. - Cost Efficiency
Achieved near real-time performance at a lower cost compared to high-performance GPUs like the A100. - User Satisfaction
Significantly improved user satisfaction through optimized search response times and model accuracy.
7. Conclusion
Cross-Encoder-based reranking provides high accuracy in search systems and has established itself as a powerful tool for modeling complex contextual interactions. However, these models can become major bottlenecks in real-time search systems due to high computational costs and memory usage. To address these challenges, lightweight techniques such as pruning, distillation, and quantization, along with various engineering optimizations, have been introduced, each with its own advantages and limitations.
Allganize has significantly improved the performance of real-time search systems by implementing not only model compression techniques but also engineering optimizations such as hardware optimization (L4 GPU), serving platform optimization (Triton Server), and Dynamic Padding.
Through these optimizations, the overall response speed has improved by more than 10 times, with perceived speed improvements of up to 20–30 times thanks to dynamic padding.Allganize is continuously developing new technologies to provide reliable and fast services. Moving forward, the company plans to research and adopt the latest technologies, such as INT quantization and embedding model optimization. In particular, since support for quantization in embedding models is currently limited, Allganize aims to independently develop lightweight technologies based on TensorRT and CUDA to deliver higher efficiency at lower costs.
These innovations are expected to strengthen the competitiveness of real-time search systems and serve as a foundation for enhancing the user experience.