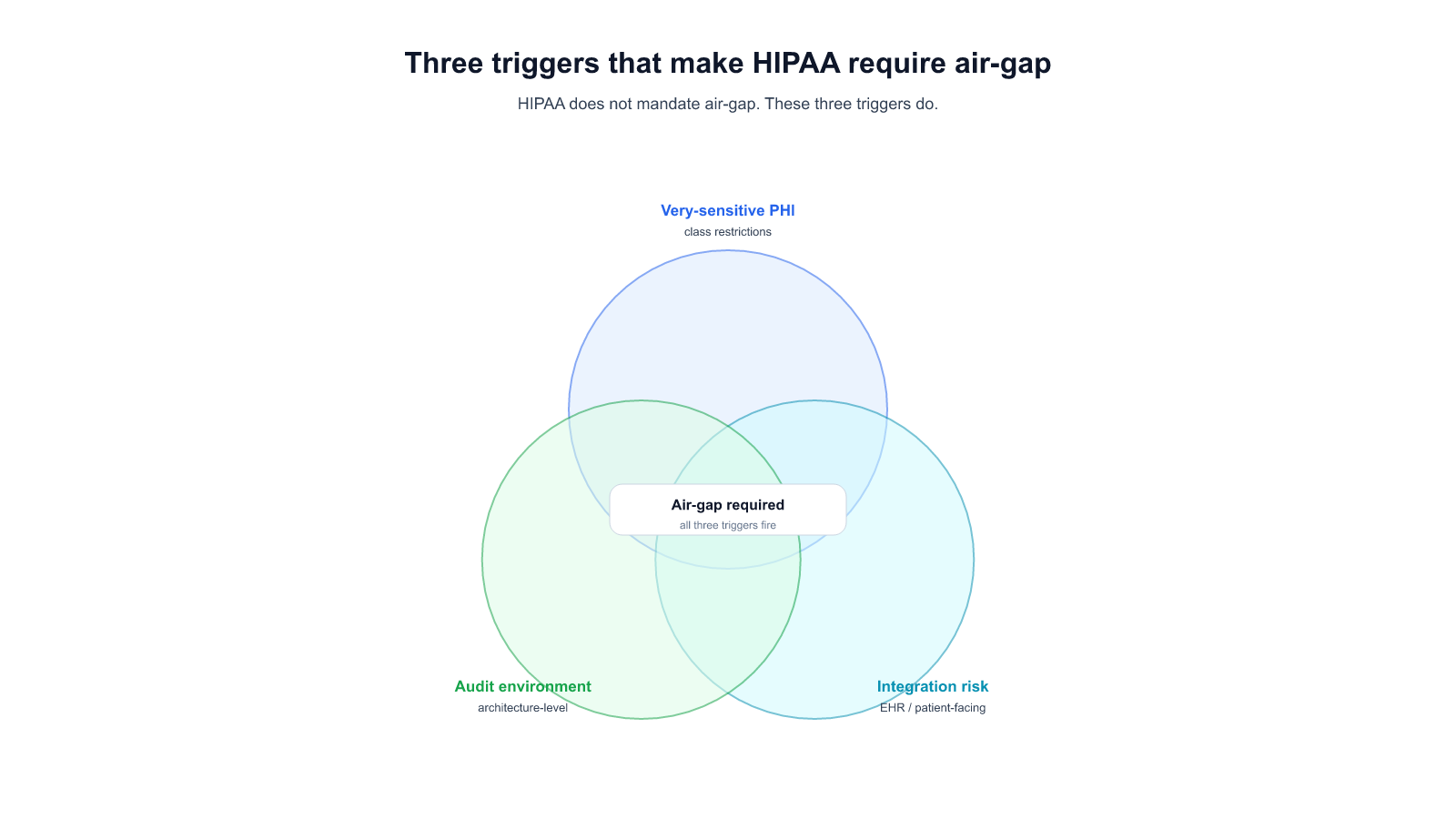
Allganize has developed an automated performance evaluation system for large language models (LLMs), reducing validation time from 2 hours to 10 minutes. This system integrates traditional evaluation methods like BLEU and BERT Score with new approaches such as LLM Eval and the RAGAS library. While these methods initially had a 20% error rate, Allganize improved accuracy by combining RAGAS with other tools like TonicAI and GenAI, bringing the error rate down to 5%. Their goal is to refine this process further, incorporating user preferences and reducing error rates below 1%.
With the flood of LLMs, how are you conducting performance evaluations? Allganize has reduced the validation process from 2 hours to 10 minutes through automated performance evaluation. In this post, we share Allganize’s experience, including the concept and necessity of LLM performance evaluation, the use of LLM Eval, and methods for minimizing error rates.
As numerous large language models (LLMs) emerge, many claim impressive performance with various evaluation metrics. In enterprise AI projects, LLM performance evaluation is critical. What businesses seek is the ability to find accurate answers from vast internal documents and data. However, identifying the most suitable LLM for a company can be a time-consuming process.
Allganize offers optimized LLMs tailored for enterprises and has also automated the performance evaluation process to objectively prove their effectiveness. Jeong-Hoon Lee, head of Allganize's RAG team, shares the know-how behind automating LLM performance evaluation, reducing the time from 2 hours to just 10 minutes.
1. The Concept and Necessity of LLM Performance Evaluation
With the advancements of generative models like OpenAI and Claude, performance evaluation of their responses has become more frequent. At Allganize, performance evaluations are conducted often due to the simultaneous PoC (Proof of Concept) projects with multiple clients. Evaluating the accuracy of responses is a task that requires significant time and manpower. If the performance evaluation process can be automated, clients will be able to quickly determine whether to adopt RAG (Retrieval-Augmented Generation) solutions.
There are two main methods for evaluating generative responses. The first is N-gram matching methods, such as BLEU, ROUGE, and METEOR. These methods evaluate the similarity between the generated response and the correct answer based on word matching. However, BLEU scores, for example, only measure word-level matches and do not account for grammatical accuracy or contextual coherence. For instance, if a model generates "The mat is on the cat" instead of "The cat is on the mat," the BLEU score might still be high, even though the sentence meaning is completely different.

The second method is evaluating the semantic similarity between the generated response and the correct answer, such as using BERT Score. BERT Score converts sentences into embedding vectors using the BERT model. These embedding vectors are numerical representations that reflect the meaning of the text. The cosine similarity between the vector of the generated response and that of the correct answer is then calculated. Since BERT Score captures semantic similarity, it can recognize that "The cat is on the mat" and "The cat is sitting on the rug" are related.
However, BERT Score has its limitations. BERT can only process up to 512 tokens, meaning that if a text exceeds this limit, part of the sentence will be truncated, potentially missing critical information. Additionally, BERT is pre-trained on specific domain data, which makes it less effective when dealing with data outside of its training scope.

Due to these limitations, LLM Evaluation methods have recently gained attention. LLM Evaluation assesses the generated response by considering grammatical accuracy, contextual coherence, and semantic similarity in a comprehensive manner. This allows for a more accurate evaluation of the performance of generative models, providing a more reliable comparison of their capabilities.
2. What is LLM Eval?
A prominent library for LLM Evaluation is RAGAS. RAGAS (Retrieval-Augmented Generation Assessment) is a well-known Python-based open-source library that provides tools for evaluating RAG pipelines. It allows users to assess the performance of LLMs by evaluating various aspects of their responses, making it a valuable resource for those looking to automate and improve the accuracy of LLM performance evaluations. Here are the key drivers:

Faithfulness measures the consistency of a generated response with the given context. It is calculated by comparing the generated answer to the context, and the score is scaled between 0 and 1, where a higher score indicates better alignment and reliability. This metric ensures that the generated output remains faithful to the original information provided in the context.

Answer Relevance evaluates how closely the generated response is related to the given prompt (question). Responses that contain incomplete or redundant information are assigned lower scores. This metric ensures that the generated answer is both relevant and focused on addressing the prompt accurately.

Context Precision is a retrieval-related metric that evaluates how well the system retrieves items related to the ground-truth found in the context, ranking them highly. It is calculated as a value between 0 and 1 based on the question and context, with a higher score indicating better performance. A higher precision score suggests more accurate retrieval of relevant context for the generated response.

In January 2024, the Allganize AI team conducted experiments on automated performance evaluation using RAGAS. We carried out various tests with real data, and the performance metrics were based on the error rate between human evaluations and LLM Eval results. However, when using only RAGAS, we found an error rate of around 20%, leading us to conclude that it was challenging to use RAGAS as-is in practical applications. Below is a table summarizing the evaluation results based on real data.

The Confusion Matrix and distribution chart below reflect the error rate based on Allganize's internal data evaluation. In the Confusion Matrix on the lower right, you can see that for RAGAS-Relevancy, only 16 out of 54 instances show a match where both the predicted and actual labels are "Yes." This highlights a significant discrepancy between predicted relevancy and actual results, contributing to the overall error rate in the evaluation.


3. Combined Approach
Since the error rate from using only RAGAS was too high, we adopted a new approach. Instead of relying solely on RAGAS, we combined other evaluation methods, such as TonicAI, GenAI, and Allganize's own evaluation method based on Claude. TonicAI focuses on evaluating the similarity between the generated response and the correct answer. GenAI, in contrast, evaluates not only similarity but also accuracy by structuring prompts accordingly.
For each dataset, we applied multiple evaluation methods independently. The final result was determined by a majority vote across these methods. If the evaluation produced scores, we classified them as either correct (O) or incorrect (X) based on a predetermined threshold. This ensemble approach helped to reduce errors and improve the overall reliability of the evaluation.

By using the combined approach, the error rate, which was over 20%, decreased to below 5%. The error rate is calculated as (number of errors/total number of cases), with a lower rate indicating better performance.
The table below shows the results of adding only TonicAI to the previous experiment and applying the ensemble evaluation method, reducing the error rate from 18% to 5%. Through this experiment, we confirmed that the ensemble approach is effective in reducing the error rate.

Afterwards, we conducted various experiments by adding GenAI and Allganize’s evaluation methods. We experimented with excluding certain evaluation methods and adjusting the thresholds to find the optimal evaluation method. The criteria for good performance, as in previous experiments, was the error rate compared to human evaluations.
V1
V2
V3

4. Future Work
Despite the improvements in the automated performance evaluation method, there are still areas that need enhancement. One major limitation is the inability to incorporate human preferences into the evaluation of responses. The current automated methods focus on checking whether the generated response contains the content of the correct answer, but they do not account for user preferences.
For example, a response that is overly long, as shown below, may not be preferred by users. However, since it includes all the information from the correct answer, the automated evaluation method would still consider it correct. This highlights the need for future work to incorporate factors like brevity and user preference into the evaluation process.

The current error rate for automated performance evaluation is around 5%. While this is a significant improvement from the initial 20%, it still implies an error range of up to 10%. To address this, we are conducting various experiments aimed at reducing the error rate to below 1%.
Thanks to the LLM Eval-based automated performance evaluation method, the time required to validate 100 data points has decreased from 2 hours to under 10 minutes. This allows us to quickly and accurately evaluate more customer data. Why not try out Alli’s Auto Evaluate to conduct fast and simple performance evaluations?
Are you ready to automate your LLM performance evaluations and save time? Allganize’s automated evaluation solution can help you reduce validation time from 2 hours to just 10 minutes! Reach out today to learn how we can optimize LLMs for your enterprise and enhance your evaluation process with our cutting-edge methods. Contact us now for more information and to see how our innovative solution can benefit your business.
Lorem ipsum dolor sit amet, consectetur adipiscing Aliquam pellentesque arcu sed felis maximus
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Curabitur maximus quam malesuada est pellentesque rhoncus.
Maecenas et urna purus. Aliquam sagittis diam id semper tristique.
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Curabitur maximus quam malesuada est pellentesque rhoncus.
Maecenas et urna purus. Aliquam sagittis diam id semper tristique.
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Curabitur maximus quam malesuada est pellentesque rhoncus.
Maecenas et urna purus. Aliquam sagittis diam id semper tristique.
Stay updated with the latest in AI advancements, insights, and stories.