Innovating AI-based search with Rerankers: Understanding context and reasoning
To minimize hallucinations in AI and improve accuracy, retrieval-augmented generation (RAG) relies on advanced retrieval methods. Allganize's "Alli" Reranker enhances RAG by combining Cross-Encoder precision with efficient multi-stage retrieval, balancing speed and contextual accuracy. Experiments show 14% accuracy gains with practical latency, revolutionizing context-driven information retrieval.
To reduce hallucinations in generative AI and provide more accurate answers, the performance of RAG (Retrieval-Augmented Generation) is critical. Significant technical advancements have been made to enhance the retrieval of the most accurate information from documents. Among these, Allganize's Alli has introduced a more efficient Reranking strategy while maintaining precision.
Allganize's RAG team, including Mr. Hanjoon Jo and Team Leader Junghoon Lee, explains their Reranker, which is designed to understand context and reason effectively.
1. Overview
1.1 Background
Advancements in Information Retrieval Technology
Information retrieval technology has continuously evolved in response to the exponential growth of data and changing user demands. In its early stages, retrieval relied on simple keyword matching, which revealed significant limitations in both efficiency and precision.
The Emergence of BM25
BM25 introduced a method for ranking search results by evaluating word importance using statistical techniques like TF-IDF. While it improved search efficiency, BM25's focus on word frequency and placement meant it could not understand the contextual meaning of queries or documents.
The Rise of Semantic Search
With advancements in deep learning, vector-based retrieval models such as Bi-Encoders enabled semantic search, going beyond simple keyword matching. Bi-Encoders transform both queries and documents into vectors to evaluate their similarity, providing efficiency in large-scale data processing. However, Bi-Encoders struggled to capture detailed interactions between queries and documents.
Introduction of Advanced Deep Learning Models
To address these limitations, sophisticated models like Cross-Encoders were developed. Cross-Encoders take both queries and documents as a single input, allowing for detailed evaluation of contextual interactions, thereby offering the highest level of precision. Consequently, the paradigm of information retrieval has shifted from merely "finding" data to "understanding" the contextual relationship between queries and documents.
1.2 Motivation
The Need for Reranking Strategies
While Cross-Encoders significantly improve search quality, their high computational cost makes it impractical to apply them to all retrieved documents. To address this challenge, Reranking strategies have been developed to balance efficiency and precision. Reranking optimizes search precision while conserving computational resources, making it an essential component in modern search system design.
2. Comparison and Analysis of Search Models
2.1 BM25: Traditional Statistical Keyword-Based Search Model
Overview
BM25 (Best Matching 25) is a classical information retrieval model based on statistical principles. It ranks documents according to their relevance to a query by evaluating the frequency and distribution of query terms within the documents. BM25 is an enhanced version of TF-IDF, offering refinements in term weighting and document length normalization.

How BM25 Works
BM25 is a keyword-matching statistical model that calculates the similarity between queries and documents based on the importance of words. It uses term frequency (TF) and inverse document frequency (IDF) to compute relevance scores. The model also adjusts scores based on document length to prevent excessively long documents from receiving disproportionately high scores.
Strengths
- Simplicity and Speed: The algorithm is computationally lightweight and operates efficiently even on large datasets.
- Keyword Matching: Well-suited for straightforward queries where keyword relevance is paramount.
- Domain-Specific Effectiveness: Performs exceptionally well in fields like legal documents and academic papers, where precise keyword matching is critical.
Limitations
- Lack of Contextual Understanding: BM25 cannot interpret the semantic or contextual meaning of queries and documents.
- Struggles with Synonyms and Polysemy: It fails to differentiate between synonyms (e.g., "AI" and "artificial intelligence") or the various meanings of a word, potentially leading to inaccurate results.some text
- For example, when searching for "effects of AI adoption," BM25 might return irrelevant documents that contain "AI" but are unrelated to the intended context.
2.2 Bi-Encoder: Deep Learning-Based Semantic Search

How Bi-Encoder Works
The Bi-Encoder independently converts both the query and document into vector representations, then calculates the similarity between the two vectors. It leverages language models (e.g., BERT, RoBERTa) to create embeddings that reflect the contextual meaning of words. Bi-Encoders support parallel processing, making them efficient even for large-scale datasets.
Strengths
- Semantic Similarity: Captures the meaning-based relationship between queries and documents, without relying on exact keyword matches.
- Efficiency: Enables parallel processing, ensuring fast search speeds despite higher computational costs compared to BM25.
- Scalability: Well-suited for handling large datasets with precomputed embeddings.
Limitations
- Lack of Fine-Grained Interaction: Since queries and documents are processed independently, Bi-Encoders cannot reflect detailed interactions between specific terms in the query and document.
- Loss of Key Information in Long Documents: For longer documents, crucial information may get diluted or "averaged out" in the vector representation, reducing retrieval precision.
2.3 Hybrid Search: Combining BM25 and Bi-Encoder

How Hybrid Search Works
Hybrid Search combines the scores from BM25 and Bi-Encoder to generate search results. The combination formula is typically:
Hybrid Score = α * BM25 Score + (1 - α) * Bi-Encoder Score
This approach leverages BM25’s keyword matching ability and Bi-Encoder’s contextual semantic analysis simultaneously. The parameter α controls the weighting of the two models, allowing for customization based on specific domain requirements.
Strengths
- Balanced Retrieval: Provides a balanced utilization of keyword-based and semantic-based search, improving relevance in a wide range of use cases.
- Domain Optimization: The weighting between BM25 and Bi-Encoder can be adjusted (α) to suit specific domains or search scenarios. For instance:some text
- Higher BM25 weighting for keyword-heavy domains like legal or academic documents.
- Higher Bi-Encoder weighting for domains requiring semantic understanding, like conversational queries.
Limitations
- Fixed Weighting: The static weighted combination formula struggles to dynamically adapt to complex query-document interactions.
- Incomplete Contextual Understanding: Like Bi-Encoders, Hybrid Search does not fully capture fine-grained interactions between queries and documents, as it still relies on independently processed vectors.
2.4 Cross-Encoder: Advanced Deep Learning Search Model

How Cross-Encoder Works
The Cross-Encoder combines the query and document into a single input to evaluate the interaction between the two texts. It assesses the relationships between individual words in the query and document, providing high-precision results. By using large language models like BERT, the Cross-Encoder maximizes the understanding of contextual meaning and semantic relationships.
Strengths
- Comprehensive Interaction Analysis: Cross-Encoders evaluate the complex relationships between the query and document comprehensively, offering the highest level of precision.
- Detailed Understanding: The model effectively assesses the relationship between the query's intent and the document's detailed content.some text
- For example, for the query "legal application cases," the Cross-Encoder can accurately retrieve documents that include both specific legal clauses and examples of their application.
Limitations
- High Computational Cost: Cross-Encoders are computationally intensive, making them unsuitable for direct application to large datasets.
- Slow Processing Speed: Their joint processing of each query-document pair results in slow response times, limiting their practicality in real-time search systems or environments where speed is critical.
2.5 Summary of Model Comparisons

2.6 Summary and Conclusion
BM25, Bi-Encoder, Hybrid Search, and Cross-Encoder each offer unique search strategies with distinct strengths and limitations:
- BM25: Highly efficient for keyword-based searches, ideal for domains requiring exact keyword matching.
- Bi-Encoder: Improves precision by capturing contextual meaning, making it suitable for semantic search.
- Hybrid Search: Balances the efficiency of BM25 with the semantic accuracy of Bi-Encoders, providing a versatile approach.
- Cross-Encoder: Delivers the highest precision through detailed query-document interaction but incurs high computational costs.
Each model is suited to specific environments and objectives. Selecting the optimal combination of these models based on the use case and constraints (e.g., speed, precision, scalability) is essential for designing an efficient and accurate search system.
3. Reranking Strategies

3.1 Limitations of Cross-Encoder and the Need for Reranking
Strengths of Cross-Encoder
The Cross-Encoder combines the query and document into a single input, enabling it to evaluate detailed interactions between the two.
- Highest Precision:
- Cross-Encoder provides the most accurate evaluation of the contextual relationship between the query and document.
- For example, it can distinguish between subtle differences in meaning, such as identifying documents that precisely align with the intent behind a query.
- Contextual Understanding:
- It captures the semantic connections between the query and document better than models like BM25 or Bi-Encoders.
- This ability ensures that documents relevant to the query's deeper intent are prioritized.
Limitations of Cross-Encoder
- High Computational Cost:
- Cross-Encoder requires pairwise computation for each query-document pair, which is computationally intensive.
- Applying it to a large dataset is inefficient and resource-consuming.
- Real-Time Processing Challenges:
- It struggles to return results quickly in real-time environments, especially when dealing with vast document collections.
- Bottleneck Issues:
- Directly applying Cross-Encoder to an entire dataset creates a bottleneck, exhausting computational resources and slowing down the retrieval process.
Need for Reranking
Reranking strategies were introduced to leverage the strengths of Cross-Encoders while overcoming their limitations.
- Efficient Candidate Generation: In the initial retrieval stage, models like BM25 or Bi-Encoders quickly and efficiently generate a candidate pool of documents from the entire dataset.
- Selective Application of Cross-Encoders: Cross-Encoders are then applied only to this smaller set of candidates, focusing computational resources where high precision is most needed.
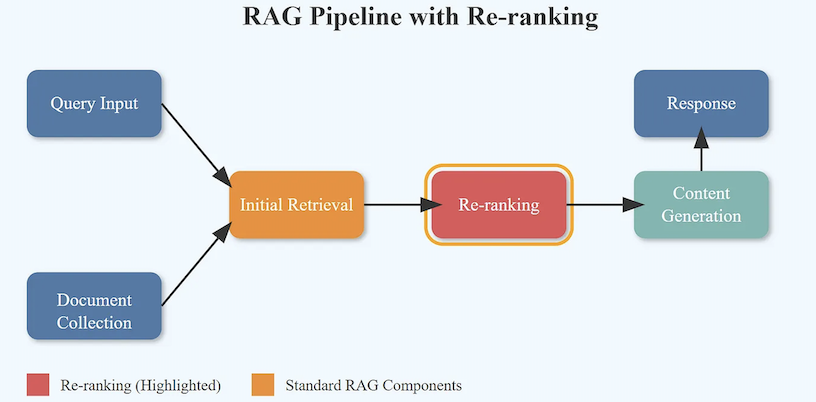
3.2 How Reranking Works
Reranking operates in a multi-stage process designed to enhance search precision while maintaining computational efficiency. The process includes the following steps:
1. Initial Candidate Generation
- Using Hybrid Search:
- In the initial search stage, models such as BM25 or Bi-Encoders are used to retrieve the most relevant documents.
- The top-ranked documents are selected as the Top-K candidate set, significantly narrowing down the number of documents to process.
- Efficiency:some text:
- By focusing only on a small candidate set, the system avoids processing the entire dataset, ensuring computational efficiency while preserving relevance.
2. Reordering with Cross-Encoder
- Applying Cross-Encoder:
- The Cross-Encoder is applied to the Top-K candidate set to evaluate the fine-grained interactions between the query and each document.
- It uses a Cross-Attention mechanism to model the relationships between every word in the query and the document.
- Similarity Scoring:
- Each document in the candidate set is scored based on its contextual and semantic similarity to the query.
- Documents with higher relevance scores are ranked higher in the final results.
3. Final Result Delivery
- Providing Reranked Results:
- The reranked list, with documents ordered by their refined relevance scores, is presented to the user.
- Enhanced Precision:
- Compared to the initial retrieval stage, the reranked results are more precise and relevant, improving the user's satisfaction with the search system.
3.3 How Reranking Addresses Cross-Encoder's Limitations
Reranking effectively mitigates the limitations of Cross-Encoders by introducing a multi-stage approach that balances efficiency and precision. Here’s how it resolves these challenges:
1. Reduction of Computational Costs
- Selective Application:
- Instead of applying the Cross-Encoder to the entire dataset, it is only applied to the Top-K candidate documents identified during the initial retrieval phase.
- For example, if the dataset contains tens of thousands of documents, only the top 64 candidates are processed by the Cross-Encoder, significantly reducing computational overhead.
- Resource Optimization:
- This targeted application minimizes resource consumption while maintaining the benefits of fine-grained evaluation for a small subset of documents
2. Preservation of Precision
- Robust Candidate Pool:
- Even if the initial retrieval (e.g., Hybrid Search) is not perfectly precise, ensuring the correct document is included in the Top-K candidate set increases the likelihood of retrieving relevant results.
- Final Ranking Accuracy:
- The Cross-Encoder then identifies the most relevant documents within the candidate pool, ensuring that the Top-3 documents in the final ranking are highly precise and contextually relevant.
3. Balance Between Efficiency and Precision
- Efficient Initial Retrieval:
- By relying on efficient models like BM25 or Bi-Encoders during the first stage, the system ensures fast candidate generation.
- High Precision Reranking:
- Cross-Encoder’s detailed evaluation in the second stage ensures that the final results are of the highest quality.
- Practical for Real-Time Environments:
- This step-by-step approach makes it feasible to use Cross-Encoders even in real-time search systems, where both speed and accuracy are critical.
4. Experiment: Analyzing the Effectiveness of Reranking
4.1 Experiment Setup
1. Dataset
- The experiment was conducted across 8 domain-specific datasets, each containing real-world documents and queries as sample data.
- These datasets represent diverse fields to ensure robust evaluation of the Reranking strategy.
2. Model Configuration
- Reranker:
- Model: bge-m3-reranker-v2 (560M parameters).
- Applied to rerank the Top-64 candidate documents generated in the initial retrieval stage.
- Baseline:
- Hybrid Search combining BM25 and bge-m3-bi_encoder.
- Token Size:
- Both the Reranker and Baseline models were configured with a maximum token size of 4096.
3. Evaluation Metrics
- Top-N Accuracy:
- Measures the percentage of queries where the correct document is included in the top-ranked results.
- Metrics used:
- Top-3 Accuracy: Evaluates precision for the top 3 results.
- Top-5 Accuracy: Evaluates precision for the top 5 results.
- Top-10 Accuracy: Evaluates precision for the top 10 results.
4. Hardware Environment
- GPU:
- Experiments were conducted on NVIDIA A100 (40GB) GPUs using Google Colab.
- Precision:
- The Reranker was run in Half Precision (FP16) mode to reduce memory usage and speed up computations.
- Processing Time:
- On average, the additional processing time for reranking a candidate set of 64 documents was approximately 525.76ms.
4.2 Experiment Results
Effectiveness of Reranker
- The Reranker significantly improved search quality across all datasets compared to the Baseline (Hybrid Search).
- Notable improvements in Top-3 and Top-5 Accuracy:
- Achieved an average performance gain of over 10% in these metrics compared to the Baseline.
- This highlights the Reranker’s ability to accurately identify and prioritize the most relevant documents within the candidate set.
Balance Between Latency and Accuracy
- Optimal Candidate Size:
- When the candidate pool size is set to 64, the balance between search accuracy and processing time is most appropriate.
- This candidate size ensures that enough relevant documents are included for effective Reranking, while keeping computational overhead manageable.
Average Additional Processing Time:
- The Reranker introduces an average additional processing time of approximately 525.76ms (0.5 seconds) per query.
- This latency is low enough to be practical for most real-time search applications.
- Performance Improvement:
- This configuration achieves up to 14% improvement in search accuracy, demonstrating the Reranker’s ability to significantly enhance precision while maintaining acceptable response times.
4.3 Performance Improvement Summary by Customer Dataset
The table below highlights the performance improvements achieved by the Reranker compared to the Baseline (Hybrid Search) for each customer dataset. Metrics include Top-3, Top-5, and Top-10 Accuracy, demonstrating the precision gains across various domains.

4.4 Conclusion
Performance Improvement
- Significant Top-3 accuracy improvements were observed in Public, Legal, and Energy domains.
- The Reranker model significantly outperformed the Baseline in most domains.
Efficiency and Accuracy
- A candidate pool size of 64 provided the optimal balance between accuracy and processing time.
- Achieved up to a 14% performance improvement with an average latency of 0.5 seconds.
Exceptional Cases
- No performance difference was observed between Reranker and Baseline in the Finance (Brokerage) domain.
- This indicates that the effectiveness of search models can vary depending on domain-specific or data-specific characteristics.
5. Reranker Operation Example
5.1 Handling Multiple Conditions and Contextual Interactions
Features:
- Understands the contextual meaning of queries with complex conditions and retrieves the most relevant documents.
- Limitations of BM25 + Bi-encoder:
- Processes queries and documents independently, making it difficult to fully grasp the relationships between conditions.
Example Question:
"The contract states that schedule changes are possible. In this case, who should bear the additional costs?"
This type of query involves multiple conditions (schedule changes, additional costs, and responsibility) and requires a nuanced understanding of their interrelationships, which the Reranker model is designed to handle effectively.
In the above question, accurately identify the correlation between "schedule changes" and "additional cost burdens" and explore the relevant regulations.
5.2 Identifying Specific Provisions or Detailed Items
Features
- Emphasizes the importance of specific terms within a query to accurately retrieve relevant provisions.
Limitations of BM25 + Bi-encoder:
- The significance of critical terms may become diluted or assigned the same weight as other general keywords.
Example Question
- "Can you specifically explain the conditions for using leave as mentioned in Article 12 of the employment contract?"
The term "Article 12" is likely to lose its importance when using keyword-based or standalone embedding search methods. However, applying a Reranker ensures it is appropriately prioritized during retrieval.
5.3 Handling Ambiguous or Implicit Expressions
Features
- Understands the implicit meaning of a query to retrieve relevant documents effectively.
Limitations of BM25 + Bi-encoder:
- Lacks contextual understanding of abstract or generalized expressions.
Example Question
- "I think my account has been hacked. What steps should I follow to change my account password, and where else should I report it besides the bank?"
The phrase "I think my account has been hacked" should be accurately interpreted as "data breach" or "unauthorized access," enabling the retrieval of relevant documents and providing appropriate resources.
5.4 Integrating Information Across Multiple Documents
Features
- Connects information dispersed across multiple documents to provide relevant and comprehensive results.
Limitations of BM25 + Bi-encoder:
- Struggles to identify relationships between documents due to independent sentence processing.
Example Question
- "I asked my company to provide the criteria for calculating severance pay, but the related materials were not disclosed. How should I respond in this case? Should I contact the labor office?"
When laws and case precedents related to "refusal of information disclosure" are found in separate documents, this system should link them together to retrieve and present the most relevant information.
5.5 Intent-Centered Search
Features
- Selects documents by reflecting the user's perspective and intent.
Limitations of BM25 + Bi-encoder:
- Focuses on keyword-based results, often overlooking the user’s intent.
Example Question
- "I’ve filed my change of address, but the tax bills are still being sent to my old address. Do I need to handle this myself, or will the tax office update it automatically?"
Traditional search methods may overlook the user's intent of "Do I need to handle this myself?" and instead retrieve results about administrative procedures at the local government office. However, Reranker prioritizes documents that focus on the user's responsibility ("Do I") and provides relevant information accordingly.
5.6 Inference-Based Search
Features
- Retrieves documents by inferring indirect relationships between terms.
Limitations of BM25 + Bi-encoder:
- Struggles to identify indirect connections due to simple keyword matching.
Example Question
- "I’m two months away from my due date, but my company is asking me to work overtime. Is there a legal basis for me to refuse?"
If a document includes the phrase "within the first 12 weeks of pregnancy," the system needs to infer the connection between "12 weeks" and "two months before the due date" to retrieve the relevant document.
5.7 Handling Fragmented Information
Features
- Effectively combines information spread across multiple pages to retrieve comprehensive results.
Limitations of BM25 + Bi-encoder:
- Often retrieves specific pages or single documents without consolidating related information.
Example Question
- "The contract doesn’t specify additional work requests, but suddenly my workload has increased. Who is responsible in this case?"
Traditional methods might only retrieve content related to "responsibility." However, Reranker searches for both "additional work requests" and "responsibility," combining these aspects for more accurate results.
6. Conclusion
The Reranking strategy has proven to be an effective method to maximize search result precision while addressing the high computational cost of Cross-Encoders. By using Hybrid Search for initial candidate selection and then evaluating finer interactions with Cross-Encoder models, this approach achieves a balance between accuracy and efficiency.
Experimental Results:
The Reranking strategy improved Top-3, Top-5, and Top-10 accuracy across various domains, with particularly significant performance gains in public, legal, and energy sectors. These findings demonstrate that Reranking plays a crucial role in enhancing information retrieval systems.