
The blog explores the limitations of AI pre-training, focusing on data copyright issues and the constraints of the scaling law. It highlights legal challenges restricting high-quality training data and diminishing returns from expanding model size. The article introduces DeepSeek-R1, an AI model optimizing inference and reasoning through innovative architectures like Multi-Latent Attention and Mixture of Experts, showcasing a shift towards reasoning-based advancements.
AI development is reaching a turning point as traditional pre-training approaches face diminishing returns. The scaling law’s effectiveness is weakening, with performance gains slowing despite exponential increases in model size and data volume. Data scarcity and copyright restrictions further hinder AI advancements, forcing a shift toward inference-based strategies. DeepSeek-R1 exemplifies this shift, leveraging Multi-Latent Attention (MLA) and Mixture of Experts (MoE) to improve reasoning efficiency.
1. Scaling Law Limitations – Performance gains are slowing despite increased resources. GPT-4 required 10× more computational power than GPT-3 for only a 30% improvement in accuracy, signaling diminishing returns.
2. Copyright Challenges – Legal restrictions are limiting access to training data. The NYT vs. OpenAI and Getty Images vs. Stability AI lawsuits reflect a growing trend, with over 100 copyright cases filed against AI companies in 2023 alone.
3. Inference Optimization – DeepSeek-R1's MoE and MLA architectures reduce memory usage by 40% and speed up inference by 30%, allowing smaller models to match or exceed larger competitors in reasoning tasks.
4. AI Efficiency Gains – Reinforcement learning-driven models are achieving state-of-the-art results. DeepSeek-R1 outperforms previous-generation models by 15% in mathematics, 20% in coding, and 25% in logical reasoning benchmarks, proving that reasoning-focused AI can surpass brute-force scaling.
This marks a paradigm shift in AI, where the focus is moving from scaling to efficient inference and enhanced reasoning capabilities to drive future advancements.

________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________
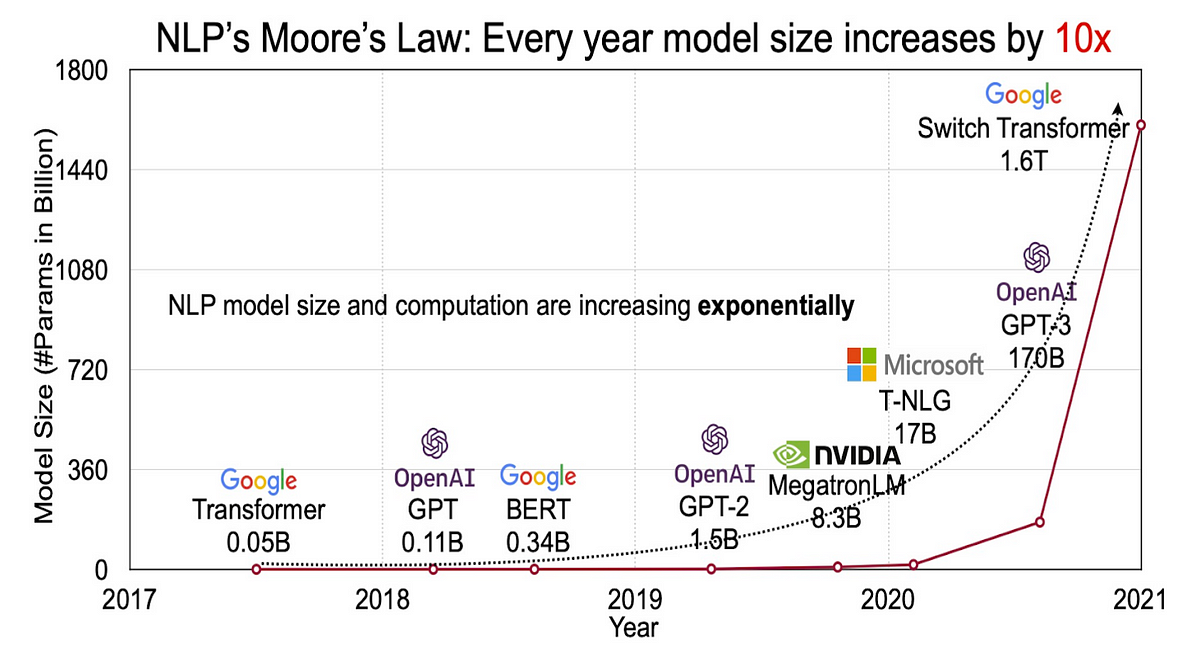
Large Language Models (LLMs) have evolved based on the scaling law, which states that increasing model size and data volume improves performance. In fact, the latest models like GPT-4, Gemini, and Claude have demonstrated outstanding capabilities in tasks such as text generation, translation, and information retrieval by leveraging vast amounts of data and computational resources.
For example, GPT-4 has significantly outperformed previous-generation models in tasks like grammar correction and code generation, driving groundbreaking advancements across the AI field. These cases clearly illustrate that the scaling law has been a key principle in the development of LLMs.
However, the AI industry is now facing a situation where simply expanding data and computational resources is no longer enough to ensure continuous performance improvements. The primary reasons cited are the scarcity of high-quality training data and restricted access to data, which are gradually weakening the effectiveness of the scaling law.
Curious about the next evolution of AI beyond scaling? Read our deep dive into DeepSeek-V3 and how it’s shaping the future of AI agents with Allganize’s LLM platform. Explore here
For AI models, the diversity and quality of training data are crucial. However, as legal and ethical controversies grow, companies and content providers are becoming increasingly reluctant to allow their data to be used for AI training. As a result, AI companies are struggling to secure new high-quality data.
These lawsuits highlight the increasing restrictions on AI models’ ability to freely utilize data, posing a major challenge to further improving performance through pre-training approaches.
Due to the shortage of high-quality data, the effectiveness of the scaling law is reaching its limits. While increasing model size and data volume still improves performance, the rate of improvement is gradually diminishing.
These perspectives suggest that new approaches are necessary for the continued advancement of AI models.
As the limitations of pre-training performance improvements become evident, the AI industry is increasingly focusing on enhancing reasoning abilities as an alternative. Models optimized for reasoning can outperform others of the same size, and in some cases, smaller models have even surpassed larger ones.
The Chinese AI startup DeepSeek has demonstrated this shift through its DeepSeek-R1 model, which combines reinforcement learning and inference optimization techniques. This model excels in mathematical reasoning, complex problem-solving, and coding tasks, highlighting the AI industry's transition toward inference-focused development.
Such examples reinforce the expectation that AI models will continue to advance by enhancing their reasoning capabilities.

As training progresses, the model takes more time to think, goes through more reasoning processes, and provides more thoughtful responses.

As training progresses, the model undergoes more reasoning processes, ultimately leading to an increase in accuracy.
DeepSeek-R1 is a state-of-the-art reasoning AI model developed by the Chinese AI startup DeepSeek, demonstrating exceptional performance in mathematics, coding, and logical reasoning. This large-scale model features 671 billion parameters and has been trained using reinforcement learning to acquire various reasoning patterns, including Chain-of-Thought exploration, self-verification, and reflection.
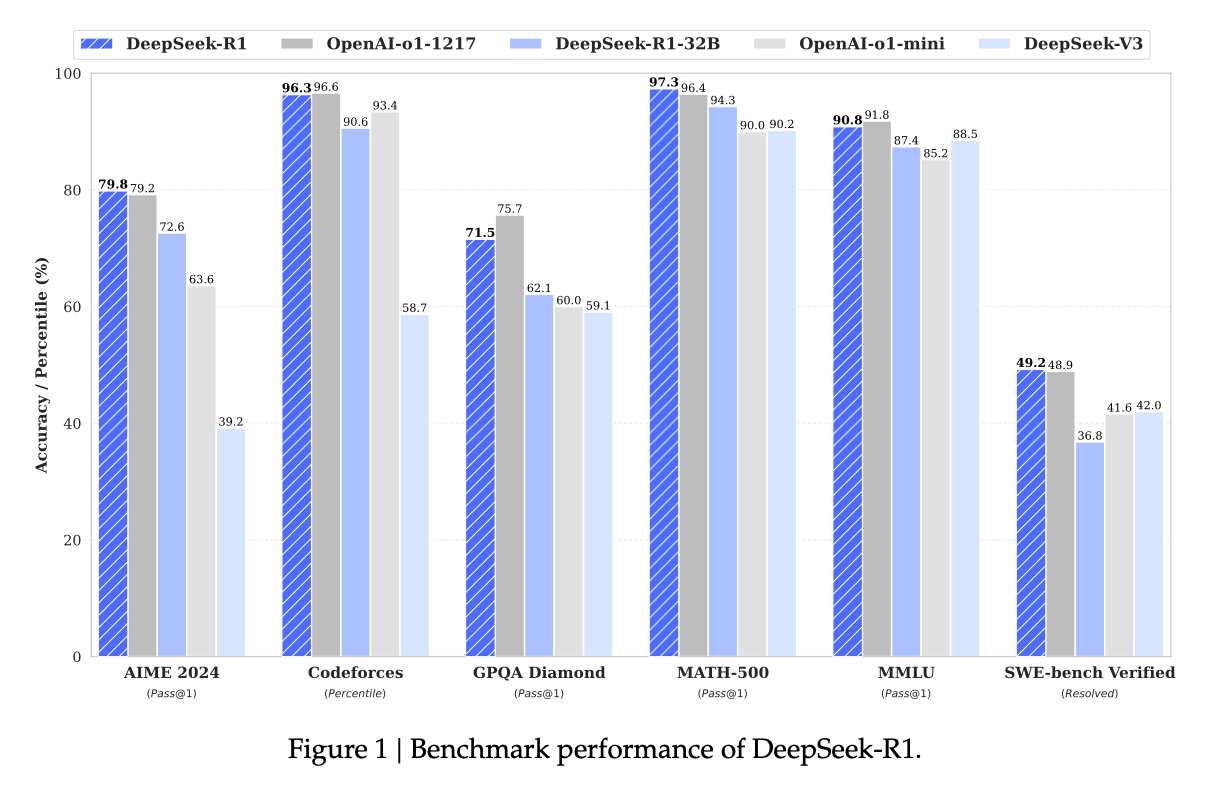
DeepSeek-R1 has achieved performance comparable to or even surpassing GPT-01 in benchmarks related to mathematics, coding, and logical reasoning.
The architecture of DeepSeek-R1 is optimized for inference, combining Multi-Latent Attention (MLA) and a Mixture of Experts (MoE) structure. These two technologies reduce memory usage during inference and minimize response latency, ensuring efficient reasoning even for large-scale tasks.

Modern large language models (LLMs) are primarily based on the Transformer architecture, where Multi-Head Attention (MHA) plays a crucial role. MHA utilizes a Query, Key, and Value (QKV) structure to capture complex data patterns.
To illustrate this with a library analogy:
In MHA, the Query constantly changes, while Key and Value remain relatively fixed. Because of this, LLMs store and utilize Key-Value (KV) caches in memory during inference. However, as model sizes grow, KV caches become excessively large, leading to increased memory usage and slower inference speeds.
To address this, DeepSeek proposed Multi-Latent Attention (MLA). MLA improves memory efficiency and enhances inference speed by converting KV into smaller-dimensional latent vectors (DKV).
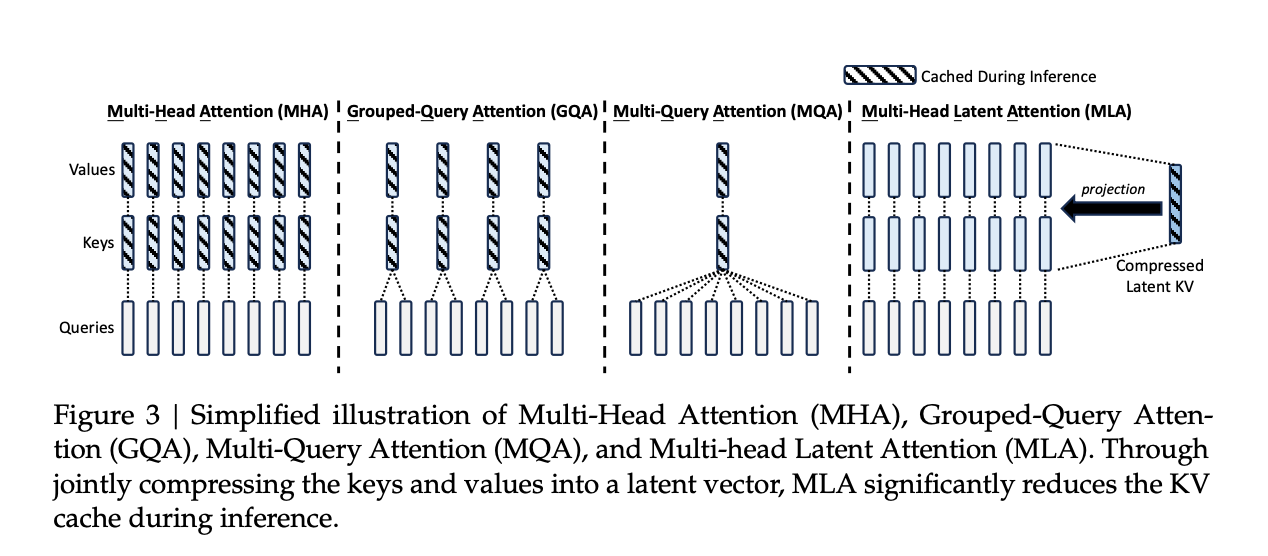
As a result, the KV cache (DKV) remains significantly smaller while minimizing information loss.
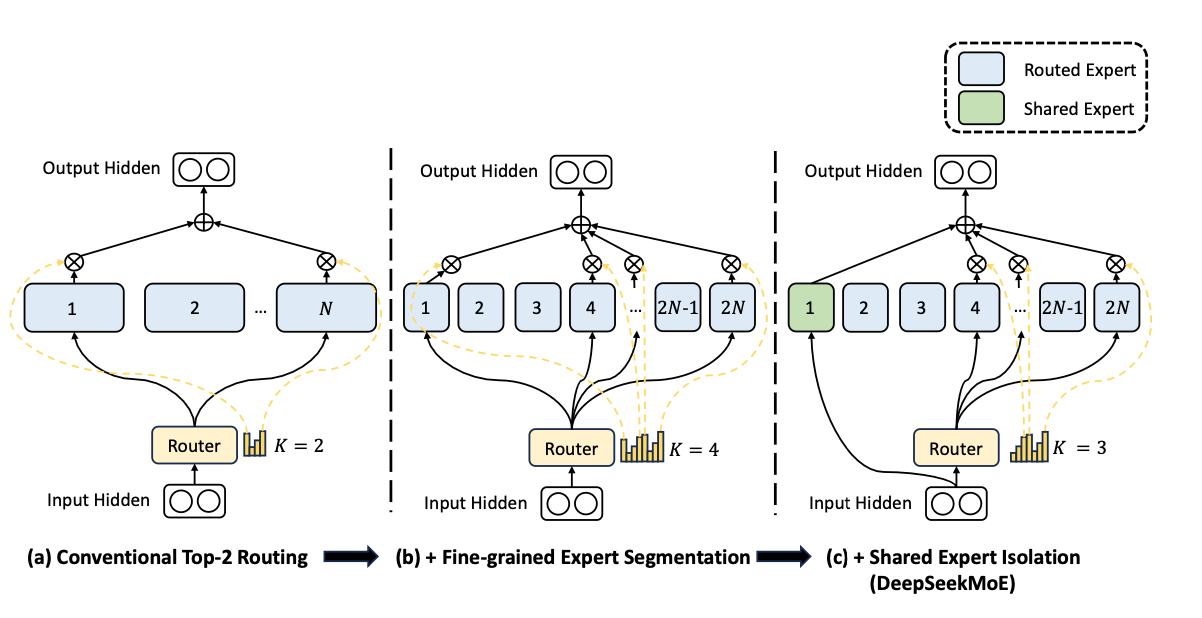
Expanding large language models (LLMs) to improve performance leads to a sharp increase in computational costs and memory usage. Traditional approaches always utilize all model parameters for every task, causing unnecessary computations and inefficiencies. To address this, the Mixture of Experts (MoE) architecture was introduced.
MoE selectively activates only a subset of expert networks (Experts) for each task, maximizing computational and memory efficiency.
DeepSeekMoE further enhances the standard MoE structure by introducing expert specialization and redundancy reduction, improving overall efficiency.
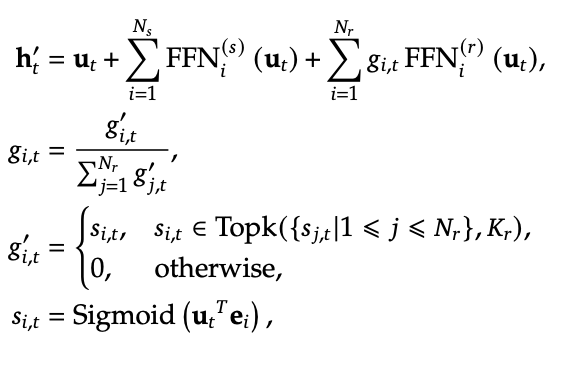
DeepSeek-R1 optimizes inference performance by combining MLA and MoE. MLA enhances memory efficiency by converting the KV cache into a lower-dimensional form, while MoE maximizes computational efficiency during inference by selectively activating only the necessary expert networks.
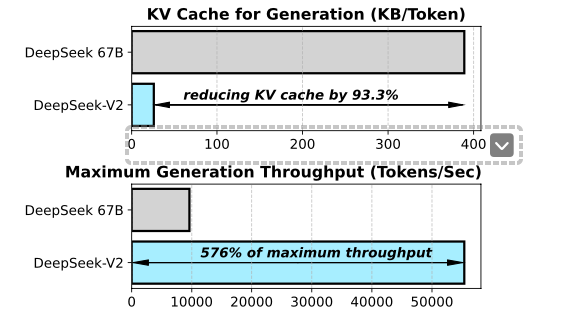
This allows DeepSeek-R1 to achieve both reduced memory usage and faster inference, while also ensuring high scalability and adaptability in large-scale data processing and various task environments.
Post-training is a concept that contrasts with pre-training, referring to the stage where a model, after large-scale pretraining, further learns human preferences and logical reasoning abilities. As mentioned earlier, the performance improvements from pre-training alone are reaching their limits, and post-training is being considered as a potential breakthrough.
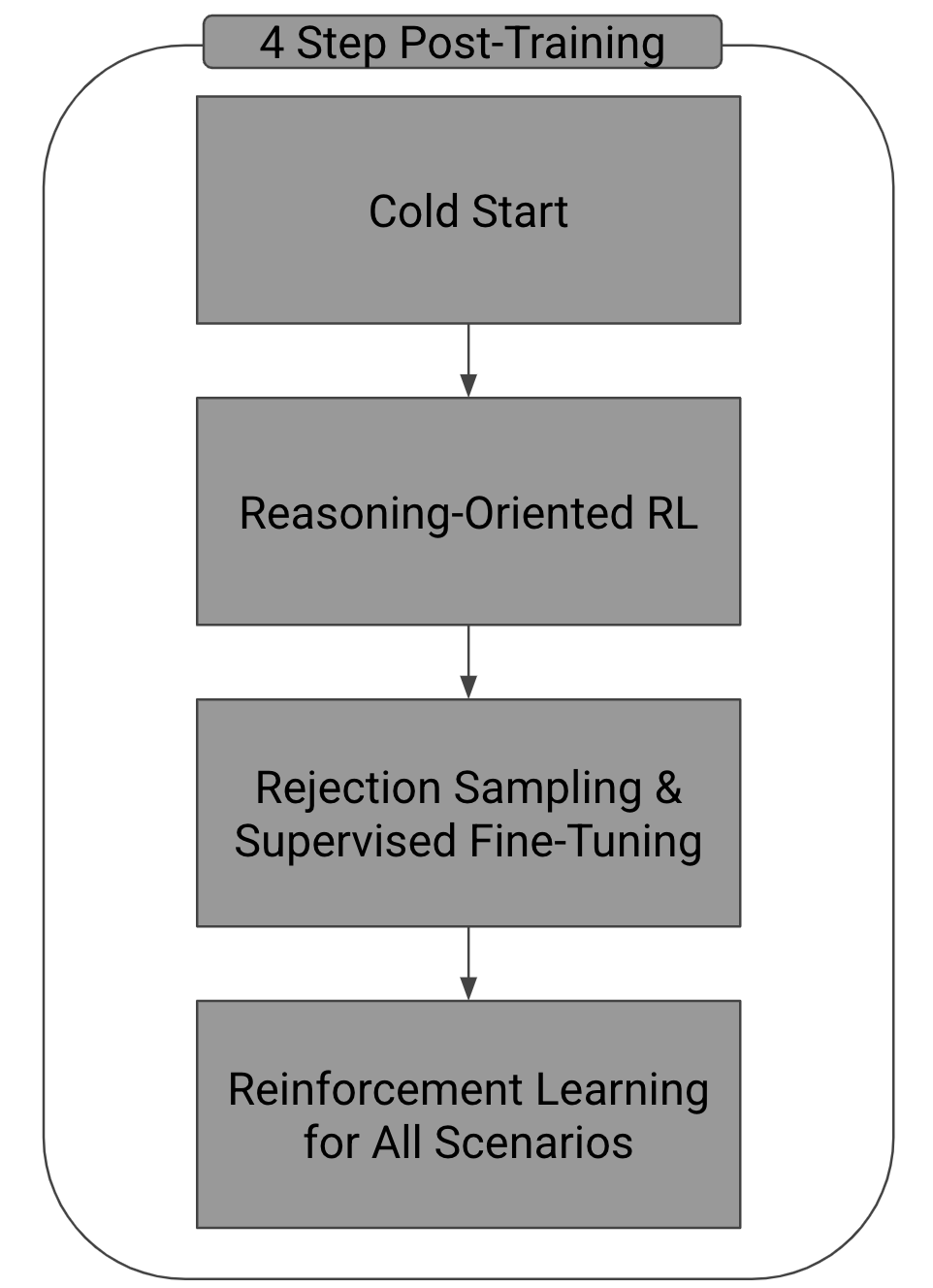
The DeepSeek-R1 model is optimized through a four-stage post-training strategy based on the pre-trained DeepSeek-V3 model, leveraging the MLA and MoE architecture. Each stage is designed to enhance the model’s reasoning capabilities and user-friendliness.
Objective:
Without human-annotated data in the initial training phase, the model's performance may be unstable or produce inconsistent responses. To address this, a small amount of high-quality cold-start data is used for fine-tuning.
Process:
Result:
The model fine-tuned with cold-start data demonstrated stable and consistent performance in the initial reinforcement learning phase.
Objective:
Enhance the model’s performance in complex reasoning-based tasks such as mathematics, coding, and logic through reinforcement learning.
Process:
This formula may initially seem complex, but it is actually quite simple. The key idea is to standardize the reward (rir_iri) generated by the model (Advantage AiA_iAi) and maximize it. Here’s a detailed breakdown:
To ensure stable learning, two constraints are applied:
Result: Achieved high performance in complex reasoning tasks.
Objective:
Further enhance the model’s diverse capabilities through additional supervised learning after reinforcement learning.
Process:
Result:
The model achieved more balanced performance across various tasks.
Objective:
Enhance both usefulness and harmlessness so the model aligns with diverse tasks and user preferences.
Process:
Evaluation Metrics:
Result:
The model successfully adapted to various data distributions, providing user-friendly and safe responses.
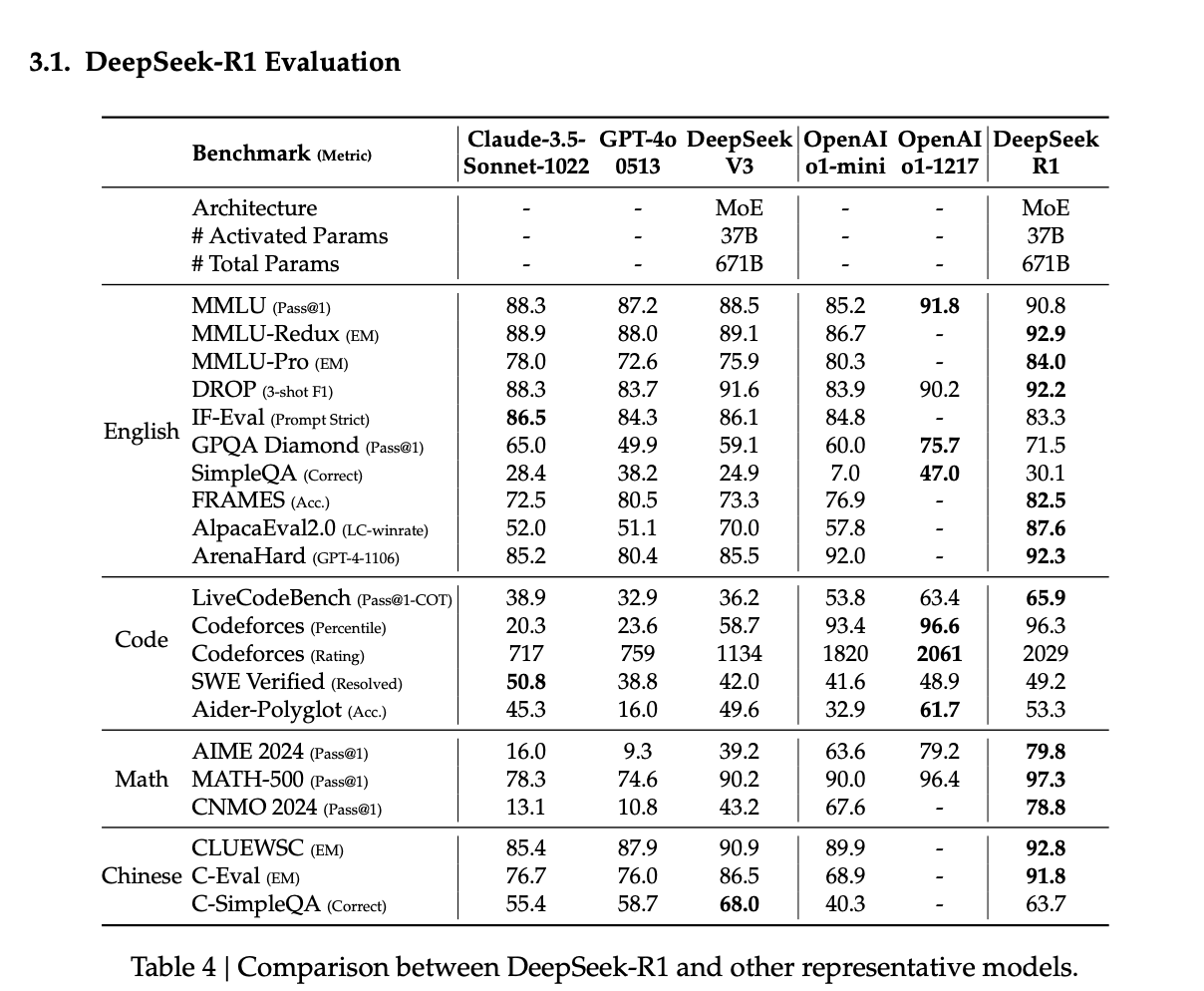
The DeepSeek-R1 model maximized its performance through a four-stage post-training strategy based on the MLA and MoE architecture. It achieved performance comparable to or exceeding competing models, including GPT-01, across various benchmarks. Notably, it demonstrated exceptional results in mathematics, highlighting the effectiveness of large-scale reinforcement learning and reward optimization.

Lorem ipsum dolor sit amet, consectetur adipiscing Aliquam pellentesque arcu sed felis maximus
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Curabitur maximus quam malesuada est pellentesque rhoncus.
Maecenas et urna purus. Aliquam sagittis diam id semper tristique.
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Curabitur maximus quam malesuada est pellentesque rhoncus.
Maecenas et urna purus. Aliquam sagittis diam id semper tristique.
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Curabitur maximus quam malesuada est pellentesque rhoncus.
Maecenas et urna purus. Aliquam sagittis diam id semper tristique.
Stay updated with the latest in AI advancements, insights, and stories.










.png)
